*은 개인적으로 외우는 방식으로 개인적 의견입니다.
정리 혹은 급한 경우에 참고하세요.
제목에 ⭐이 있으면 해당 내용 꼭 외우세요 시험에 잘나옵니다.
테이블(Table)
- 테이블은 데이터를 저장하는 데이터베이스의 가장 기본적인 오브젝트이다.
테이블 구성요소
|
로우 (Row) |
튜플, 인스턴스, 어커런스라고도 한다. |
|
컬럼 (Column) |
각 속성 항목에 대한 갑슬 저장한다. |
|
기본키 (Primay key) |
- 기본키는 후보키 중에서 선택한 주키(Main Key) 이다. - 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성이다. |
|
외래키 (Foreign key) |
- 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합을 의미한다. - 한 릴레이션에 속한 속성 A와 참조 릴레이션의 기본키인 B가 동일한 도메인 상에서 정의되었을 때의 속성 A를 외래키라고 한다. |

테이블의 구성 요소
1. 엔티티(Entity)를 테이블로 변환
- 논리 데이터 모델에서 정의된 엔티티를 물리 데이터 모델의 테이블로 변환하는 것이다.
- 엔티티를 테이블로 변환한 후 테이블 목록 정의서를 작성한다.
테이블 목록 정의서 : 전체 테이블을 목록으로 요약 관리하는 문서로 테이블 목록이라고도 한다.
예시) 테이블 목록 정의서
|
테이블 ID |
테이블명 |
타입 |
분류 |
테이블 스페이스 |
파티션 여부 |
발생주기 |
총건수 |
수정일 |
|
usr_item |
제품 |
STANDARD |
|
|
|
|
|
2019/02/20 |
|
sell_list |
판매목록 |
STANDARD |
|
|
|
|
|
2019/03/15 |
|
usr_name |
사용자 |
STANDARD |
key |
|
|
|
|
2019/03/10 |
|
sell_name |
판매자 |
STANDARD |
|
|
|
|
|
2019/03/10 |
변환규칙
|
논리적 설계 (데이터 모델링) |
물리적 설계 |
|
엔티티(Entity) |
테이블(Table) |
|
속성 (Attribute) |
컬럼 (Column) |
|
주 식별자 (Primary Identifier) |
기본키 (Primary Key) |
|
외부 식별자 (Foreign Identifier)) |
외래키 (Foreign Key) |
|
관계 (Relationship) |
관계 (Relationship) |

<주문목록>과 <주문조회> 엔티티가 <주문목록>과 <주문조회> 테이블로 변환되었다.
변환시 고려사항
- 일반적으로 테이블과 엔티티 명칭은 동일하게 하는 것을 권고한다.
- 엔티티는 주로 한글명을 사용하지만 테이블은 소스 코드의 가독성을 위해 영문명을 사용한다.
- 메타 데이터 관리 시스템에 표준화된 용어가 있을때는 메타에 등록된 당어를 사용하여 명명한다.
2. 슈퍼타입 / 서브타입을 테이블로 변환
- 슈퍼타입 / 서브타입은 논리 데이터 모델에서 이용되는 형태이므로 물리 데이터 모델을 설계할 때는 슈퍼타입 / 서브타입을 테이블로 변환해야 한다.
2-1. 슈퍼타입 기준 테이블 변환
- 슈퍼타입 기준의 테이블 변환은 서브타입을 슈퍼타입에 통합하여 하나의 테이블로 만드는 것이다.
- 서브타입에 속성이나 관계가 적을 경우에 적용하는 방법으로 하나로 통합된 테이블에는 서브타입의 모든 속성이 포함되어야 한다.

서브타입의 <방문접수> 개체에 있는 '지점코드','담당부서'와 <인터넷접수> 개체에 있는 'ID','수수료납부방법'이 슈퍼타입인 <접수> 개체에 통합되어 <접수> 테이블로 변환된다.
|
장점 |
- 데이터의 액세스가 상대적으로 용이하다. - 뷰를 이용하여 각각의 서브타입만을 액세스하거나 수정할 수 있다. - 서브타입 구분이 없는 임의 집합에 대한 처리가 용이하다. - 여러 테이블을 조인하지 않아도 되므로 수행 속도가 빨라진다. - SQL 문장 구성이 단순해진다. |
|
단점 |
- 테이블의 컬럼이 증가하므로 디스트 저장 공간이 증가한다. - 처리마다 서브타입에 대한 구분(TYPE)이 필요한 경우가 많이 발생한다. - 인덱스 크기의 증가로 인덱스의 효율이 떨어진다. |
2-2. 서브타입 기준 테이블 변환
- 서브타입 기분의 테이블 변환은 슈퍼타입 속성들을 각각의 서브타입에 추가하여 서브타입들을 개별적인 테이블로 만드는 것이다.
- 서브타입에 속성이나 관계가 많이 포함된 경우 적용한다.

슈퍼타입인 <접수> 개체에 있는 '신청자이름','접수일','수수료'가 서브타입인 <방문접수> 개체와 <인터넷접수> 개체에 각각 추가되어 <방문접수>와 <인터넷접수> 테이블로 변환된다.
|
장점 |
- 데이터의 액세스가 상대적으로 용이하다. - 뷰를 이용하여 각각의 서브타입만을 액세스하거나 수정할 수 있다. - 서브타입 구분이 없는 임의 집합에 대한 처리가 용이하다. - 여러 테이블을 조인하지 않아도 되므로 수행 속도가 빨라진다. - SQL 문장 구성이 단순해진다. |
|
단점 |
- 테이블의 컬럼이 증가하므로 디스트 저장 공간이 증가한다. - 처리마다 서브타입에 대한 구분(TYPE)이 필요한 경우가 많이 발생한다. - 인덱스 크기의 증가로 인덱스의 효율이 떨어진다. |
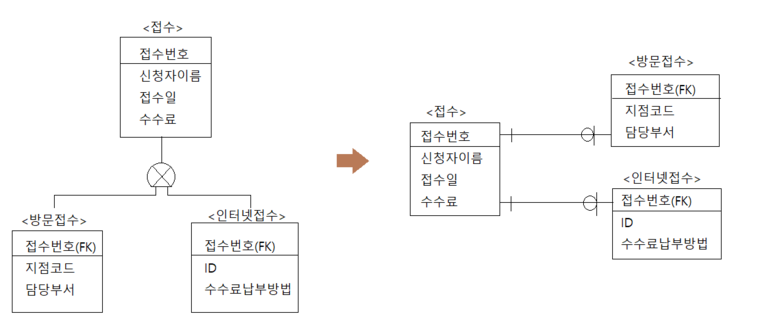
2-3. 개별타입 기준 테이블 변환
- 개별타입 기준의 테이블 변환은 슈퍼타입과 서브타입들을 각각의 개별적인 테이블로 변환하는 것이다.
- 슈퍼타입과 서브타입 테이블들 사이에는 각각 1:1 관계가 형성된다.
개별타입 기준 테이블 변환을 적용하는 경우
- 전체 데이터에 대한 처리가 빈번한 경우
- 서브타입의 처리가 대부분 독립적으로 발생하는 경우
- 통합하는 테이블의 컬럼 수가 많은 경우
- 서브타입의 컬럼 수가 많은 경우
- 트랜잭션이 주로 슈퍼타입에서 발생하는 경우
- 슈퍼타입의 처리 범위가 넓고 빈번하게 발생하여 단일 테이블 클러스터링이 필요한 경우
|
장점 |
- 저장 공간이 상대적으로 작다. - 슈퍼타입 또는 서브타입 각각의 테이블에 속한 정보만 조회하는 경우 문장 작성이 용이하다. |
|
단점 |
- 슈퍼타입 또는 서브타입의 정보를 같이 처리하면 항상 조인이 발생하여 성능이 저하된다. |
3. 속성을 컬럼으로 변환
- 논리 데이터 모델에서 정의한 속성을 물리 데이터 모델의 컬럼으로 변환한다.
일반 속성 변환
- 속성과 컬럼은 명칭이 반드시 일치할 필요는 없으나, 개발자와 사용자 간 의사소통을 위하여 가능한 한 표준화된 약어를 사용하여 일치시키는 것이 좋다.
- 컬럼명은 SQL의 예약어 사용을 피한다.
- 컬럼명은 SQL의 가독성을 높이기 위해 가능한 한 짤게 지정한다.
- 테이블의 컬럼을 정의한 후에는 한 로우에 해당하는 샘플 데이터를 작성하여 컬럼의 정합성을 검증한다.

예시
Primary UID를 기본키로 변환
- 논리 데이터 모델에서의 Primary UID는 물리 데이터 모델의 기본키로 만든다.
Primary UID를 기본키로 변환
- 다른 엔티티와의 관계로 인해 생성된 Primary UID는 물리 데이터 모델의 기본키로 만든다.
Secondary UID를 유니크기로 변환
- 논리 모델링에서 정의된 Secondary UID 및 Alternate Key는 물리 모델에서 유니크키로 만든다.
4. 관계를 외래키로 변환
- 논리 데이터 모델에서 정의된 관계는 기본키와 이를 참조하는 외래키로 변환한다.
다음은 개체 A, B로 이루어진 E-R 모델을 관계 테이블로 변환하는 방법이다.
|
1:1 관계 |
개체 A의 기본키를 개체 B의 외래키로 추가하거나 개체 B의 기본키를 개체 A의 외래키로 추가하여 표현한다. |
|
1:M 관계 |
개체 A의 기본키를 개체 B의 외래키로 추가하여 표현하거나 별도의 테이블로 표현한다. |
|
N:M 관계 |
릴레이션 A와 B의 기본키를 모두 포함한 별도의 릴레이션으로 표현한다. 이때 생성된 별도의 릴레이션을 교차 릴레이션 또는 교차 엔티티라고 한다. |
|
1:M 순환 관계 |
개체 A에 개체 A의 기본키를 참조하는 외래키 컬럼을 추가하여 표현한다. 데이터의 계층 구조를 표현하기 위해 주로 사용된다. |
5. 관리 목적의 테이블 / 컬럼 추가
- 논리 데이터 모델에는 존재하지 않는 테이블이나 컬럼을 데이터베이스의 관리 혹은 데이터베이스를 이용하는 프로그래밍의 수행 속도를 향상시키기 위해 물리 데이터 모델에 추가할 수 있다.
예) 시스템 등록 일자, 시스템 번호등
6. 데이터 타입 선택
- 논리 데이터 모델에서 정의된 논리적인 데이터 타입을 물리적인 DBMS의 물리적 특성과 성능을 고려하여 최적의 데이터 타입과 데이터의 최대 길이를 선택한다.
- 주요 타입에는 문자 타입, 숫자 타입, 날짜 타입이 있다.
- Oracle에서 자주 사용되는 데이터 유형
|
CHAR |
고정길이 문자열 Data 최대 2,000Byte 까지 저장 가능 |
|
VARCHAR2 |
가변길이 문자열 Data 최대 4,000Byte 까지 저장 가능 |
|
NUMBER |
38자릿수의 숫자 저장 가능 |
|
DATE |
날짜 저장 |
'자격증' 카테고리의 다른 글
| 정보처리기사 실기 정리& 요약 - 애플리케이션 테스트의 분류 (0) | 2020.07.15 |
|---|---|
| 정보처리기사 실기 정리& 요약 - 애플리케이션 테스트 (0) | 2020.07.15 |
| 네트워크 관리사 2급 실기 독학으로 합격하는 방법 및 관련 파일 (5) | 2020.07.08 |
| 정보처리기사 실기 정리& 요약 - 이상/함수적 종속/정규화_⭐ (0) | 2020.07.03 |
| 정보처리기사 실기 정리& 요약 - 데이터 모델의 개념 (0) | 2020.07.02 |


댓글